Автоматичний поділ голосів – забезпечує прозорість та точність в аудіозаписах
Розподіл мовців – це процес сегментації аудіозаписів за позначками мовців, який відповідає на питання «хто говорив і коли?».
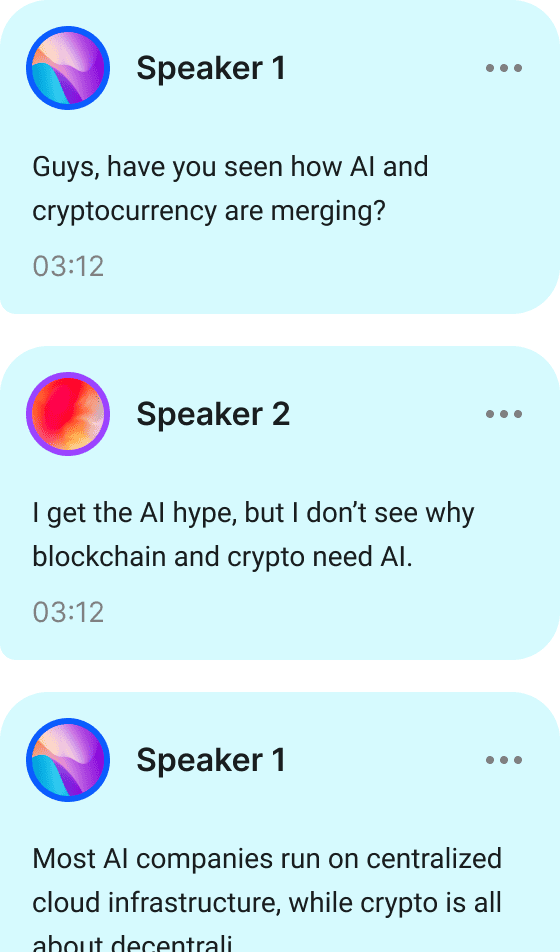
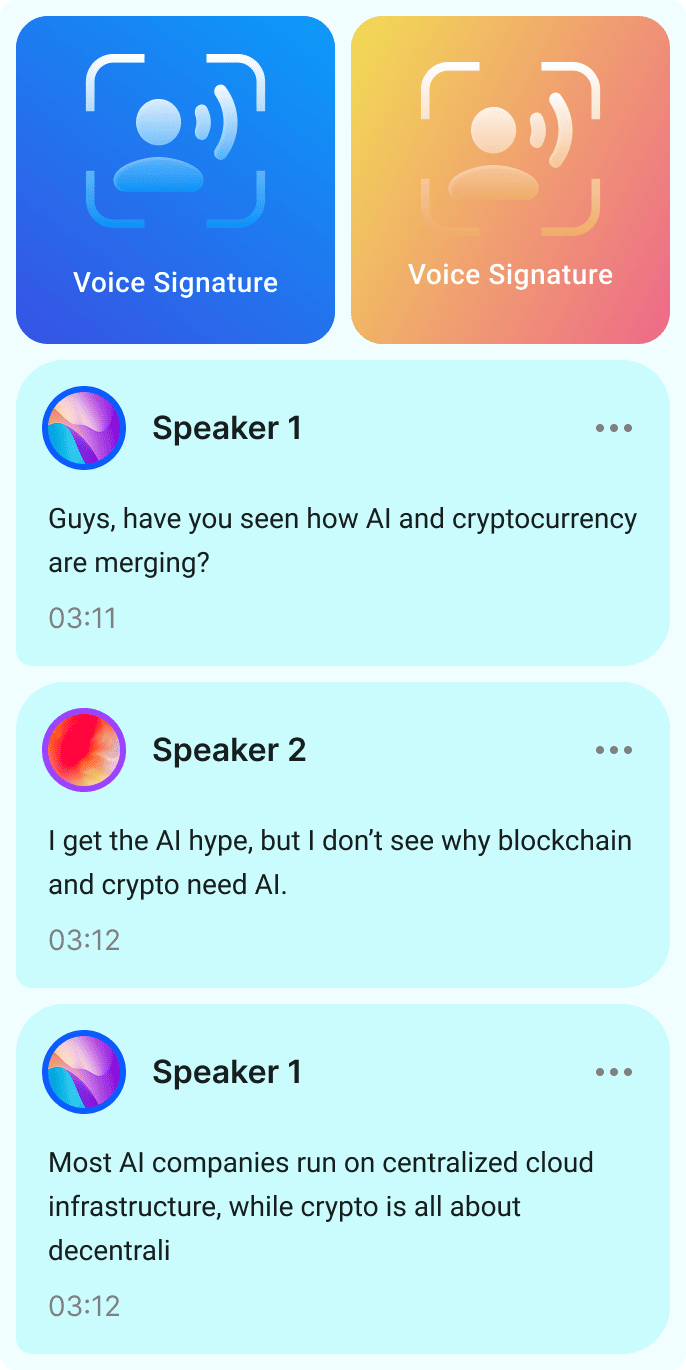
Розподіл мовців має чітке розмежування у порівнянні з розпізнаванням мовлення. Як показано на малюнку нижче, перед виконанням розподілу мовців ми знаємо «що сказано», але не знаємо «хто саме це сказав».
Отже, розподіл мовців є важливою функцією для системи розпізнавання мовлення, оскільки він дозволяє збагачувати транскрипцію мітками мовців.
Щоб визначити «хто говорив і коли», система розподілу мовців вловлює характеристики невідомих мовців і розрізняє, які ділянки аудіозапису належать якому мовцю.
Для цього система розподілу мовців витягуює характеристики голосу, визначає кількість мовців, а потім призначає аудіосегменти відповідному мовцю.
Базова схема процесу діаризації

-
Забезпечує точне визначення кожного, хто говорить.
-
Допомагає аналізувати та маркувати дані для звітування та покращення якості обслуговування.
-
Забезпечує безпеку та конфіденційність завдяки режиму офлайн.
-
Ідентифікація та поділ учасників розмови.
-
Автоматичне маркування кожного голосу для подальшого аналізу.
-
Підтримка діаризації для багатомовних записів та можливість застосування технології різними мовами.
-
Інтеграція через API: легкість підключення до існуючих CRM та аналітичних платформ
-
Правоохоронні органи та судиРозділення голосів в аудіозаписах для юридичної точності та доказової прозорості.
-
Медіа-холдингиПеретворення аудіо з інтерв'ю з кількома учасниками для підготовки та створення контенту.
-
МедицинаДокументування та аналіз медичних консультацій та конференцій.
-
Контакт-центриАналіз розмов з клієнтами, виділення операторів та клієнтів для оцінки якості обслуговування та покращення процесів.